|
|
Włodzisław |
 |
|
|
Włodzisław |
|
Szukanie informacji w Internecie lub w dużych bazach danych wymaga od użytkownika wielkiej cierpliwości i inteligencji. Programy wyszukujące informację nie potrafią zrozumieć sensu pytań, szukają jedynie słów kluczowych. Nie znając specyficznych nazw, używanych przez ekspertów z danego ośrodka, możemy mieć trudności ze znalezieniem odnośników do ich prac naukowych. Czy metody sztucznej inteligencji moga tu coś zmienić?
Inteligencja Obliczeniowa (Computational Intelligence, CI) jest dziedziną nauki zajmująca się rozwiązywaniem problemów, które nie są efektywnie algorytmizowalne, czyli takich, dla których nie znamy (lub nie istnieją) dobre metody ich rozwiązywania. Rozumienie sensu pytań bez wątpienia do takich zagadnień należy. Szukanie semantyczne informacji, w odróżnieniu od szukania według słów kluczowych, wymaga uwzględnienia sensu zadawanych pytań. Sztuczna inteligencja jest jedną z gałęzi inteligencji obliczeniowej. Kładzie się w niej nacisk na symboliczne metody reprezentacji wiedzy, poszukując reguł logicznych, pozwalających na nadanie sensu symbolom. Mogą one nabrać sens semantyczny tylko przez odwołania do kontekstu, do innych symboli zawartych w danym systemie pojęciowym. Nie jest to jednak jedyna, a ostatnio wydaje się nawet, że nie jest to najlepsza, droga do realizacji szukania semantycznego.
Inne dziedziny, z których wywodzą się metody inteligencji obliczeniowej to:
Są to ogromne obszary badań, które wypracowały swoje własne metody znajdujące szerokie zastosowania w praktyce. Wiele odnośników zebrano na stronach:
Jednym z zastosowań metod inteligencji obliczeniowej jest analiza znaczenia wypowiedzi, tekstów, próba uczenia się na podstawie analizy znanych tekstów, tworzenia systemów prowadzących dialog z użytkownikiem i systemów tłumaczących z jednego języka na drugi bez ingerencji człowieka. Znaczenie w języku potocznym zdeterminowane jest przez kontekst i może się bardzo różnić nawet w środowiskach posługujących się językiem w precyzyjny sposób. James Schlesinger, były sekretarz ministerstwa obrony USA, napisał o swoich doświadczeniach: "Zarządzanie Ministerstwem Obrony prowadziło do wielu nieoczekiwanych problemów w przekazywaniu informacji. Np. dla komandosów "zabezpieczyć budynek" oznaczało przygotowanie desantu i atak; dla piechoty oznaczało to okupację budynku, dla marynarki wysłanie człowieka by sprawdził, czy pogaszono światła w budynku, a dla lotnictwa te same instrukcje oznaczały wynajęcie budynku na trzy lata z opcją wykupu". Nawet w bliskich sobie dziedzinach inżynierii lub medycyny podobne nieporozumienia mogą się łatwo zdarzyć.
W badaniach języka naturalnego wyróżnia się zagadnienia syntaktyczne, gramatyczne, nieliniowego rozkładu gramatycznego (parsing), prozodii oraz zagadnienia semantyczne. Chociaż zagadnienia te są ze sobą powiązane w pierwszym przybliżeniu kwestie semantyczne traktowane są oddzielnie, poszukując znaczenia w relacjach danego symbolu do wiedzy, stanowiącej tło, w który m ten symbol może się sensownie pojawić. Czym jednak jest wiedza i w jaki sposób można ją analizować? Metody reprezentacji wiedzy werbalnej, zawartej w wypowiedziach symbolicznych, rozwinięte zostały w sztucznej inteligencji. Najprostsze metody odwołują się do reguł logicznych lub stwierdzeń, podsumowujących wiedzę z danej dziedziny, np:
Jeśli kolor-oczu=żółty i bilirubina=wysoka to żółtaczka.Czy człowiek używa reguł logicznych? Jedynie w nielicznych przypadkach. Próby analizy tekstów w oparciu o reguły logiczne okazały się bardzo trudne, gdyż zbyt wiele takich reguł da się zastosować w konkretnym przypadku i w efekcie nie wiadomo, które zastosować. Jest to powszechny problem, związany z "eksplozją kombinatoryczną", czyli bardzo szybko rosnącą liczbą zagadnień lub reguł, które należy zastosować by rozwiązać pierwotne zadanie. Reprezentacja wiedzy w postaci bardziej złożonych struktur, takich jak "ramy", daje większe możliwości. Ramy zawierają wiedzę ogólną o obiektach, gromadząc wewnątrz opis cech danego obiektu. Nieznane cechy mogą mieć wartości domyślne, najczęściej spotykane, mogą mieć też procedury związane z używaniem wiedzy zawartej w ramach.
| Ogólna rama, PIES |
Klasa: Zwierzę; zwierzę domowe |
Rama: PIES SĄSIADA |
Klasa: Pies |
Jednakże używanie ram nie rozwiązuje podstawowego problemu, jakim jest dobór odpowiedniej wiedzy kontekstowej do danej sytuacji, a więc wybór ram, które należy użyć. Reprezentacja wiedzy w postaci reguł lub ram działa bardzo dobrze jeśli mamy do czynienia z niewielką, ściśle zdefiniowaną domeną wiedzy, dla której znanych jest niewiele faktów. Duże nadzieje wiązano z sieciami semantycznymi, w których symbole zapisywane są w węzłach grafów, a połączenia miedzy nimi (łuki grafu) reprezentują określone relacje. Kontekst, w jakim dopuszczalne jest użycie danego słowa, zapisany jest w strukturze sieci semantycznej.
Każdy węzeł jest symbolem, powiązania są relacjami
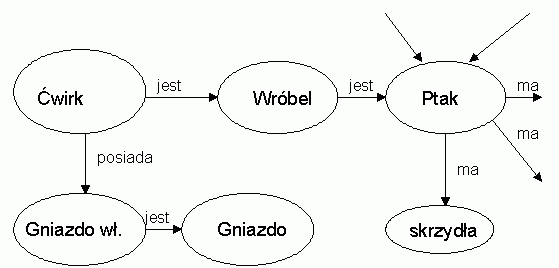
Sieci semantyczne znalazły szerokie zastosowanie w analizie tekstów, gdyż łatwo korzystać z zakodowanej w nich wiedzy, wystarczy zbadać węzły połączone z symbolami występującymi w zdaniu. Proces tworzenia sieci semantycznych jest jednak trudny i uniemożliwia powstawanie spontanicznych asocjacji - wszystkie skojarzenia trzeba przewidzieć i w jawny sposób zaprojektować. Takie podejście niewiele ma wspólnego z procesem uczenia się nowych pojęć przez ludzi.
Bardzo ważną rolę w rozumieniu języka pełnią oczekiwania i znajomość typowych sytuacji. Zrozumienie prostych historii, zawartych w notatkach gazetowych, możliwe jest przez porównywanie zawartych w nich treści ze stereotypowymi skryptami dla danych sytuacji. Takie systemy analizy tekstu działają dobrze sensownie odpowiadając na pytania dotyczące giełdy, transakcji ekonomicznych czy kronik wypadków, ale słabo sprawdzają się w szerszej dziedzinie wiedzy.
W ramach sztucznej inteligencji rozwinięto jeszcze wiele innych sposobów reprezentacji wiedzy. Znaczna część tej dziedziny dotyczy metod "inżynierii wiedzy" (knowledge engineering). Wydaje się jednak, że wszystkie symboliczne metody reprezentacji wiedzy cierpią na ten sam problem, jakim jest brak możliwości automatycznego wprowadzania nowej wiedzy o symbolu na podstawie analizy sposobu jego użycia w tekście. Tymczasem dziecko od trzeciego roku życia bardzo szybko powiększa zasób swoich słów, potrafią je prawidłowo użyć. Nowe słowa umieszczane są we właściwych relacjach w stosunku do istniejących słów w sposób spontaniczny, na podstawie analizy usłyszanych czy przeczytanych zdań. To właśnie z tego powodu Noam Chomsky uznał zdolności językowe za wrodzone a Steven Pinker napisał książkę "The language instinct", uznając rozwój mowy za rodzaj instynktu.
W jaki sposób można obdarzyć symbole sensem, tak by zawierały nie tylko arbitralne nazwy, ale intencjonalne wskazówki, umożliwiające określenie podobieństwa miedzy nimi, dodanie im otoczki wynikającej z kontekstu, w jakich się mogą pojawiać? Psycholodzy od dawna badali relacje podobieństwa semantycznego mierząc czasy reakcji na skojarzenia różnych słów ze sobą. Skojarzenia są naturalnym wynikiem organizacji sieci neuronowych kory mózgu, odpowiedzialnych za pamięć. Wierne modelowanie tych procesów jest jednak zbyt złożone. Uproszczone modele dają podobne rezultaty dużo mniejszym kosztem obliczeniowym.
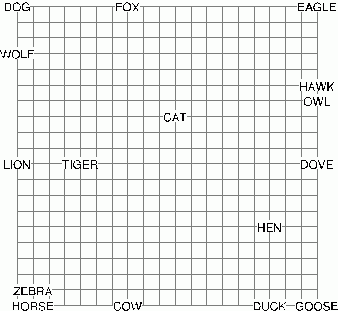
Jednym z najciekawszych projektów analizy języka, wychodzących poza symboliczną reprezentację wiedzy jest DISCERN (Miikkuleinen 1993). W projekcie tym użyto szczególnego rodzaju sieci neuronowych, zwanych sieciami samoorganizującymi się (SOM) lub sieciami Kohonena (1995). Są one odpowiedzialne za powstawanie spontanicznych skojarzeń pomiędzy symbolami, które mogą się pojawiać w podobnych kontekstach. Cały system do analizy tekstu składa się gramatycznego parsera dla zdań i większych fragmentów tekstu, pamięci epizodycznej, modułu tworzenia zdań, odpowiadania na pytania i leksykonu. Symbole docierające do leksykonu tłumaczone są na odpowiadające im reprezentacje semantyczne. Można to zrobić przypisując im wektory liczb, które odpowiadają pobudzeniom grup neuronów w mózgu. Taka rozproszona, lub wektorowa, reprezentacja, pozwala odpowiednio dobrać algorytm uczenia, modyfikujący wartości składowych tych wektorów tak, by uwzględnić kontekst, w jakich mogą się one pojawić. Symbolom przypisuje się początkowo reprezentację ortograficzna, jak i fonologiczną; pojawiają się one w zdaniach, definiujących różny sens użycia danego symbolu. Na rysunku poniżej duże wartości elementów wektora reprezentującego postać ortograficzną, fonologiczną lub semantyczną danego symbolu przedstawiane są jako ciemne pola, a małe wartości jako jasne pola. Grupy symboli, np. mężczyzna, kobieta, chłopiec, dziewczynka, chociaż różnią się znacznie z punktu widzenia pisowni czy brzmienia symbolu, przyczyniają się do powstania koncepcji semantycznej "człowiek".
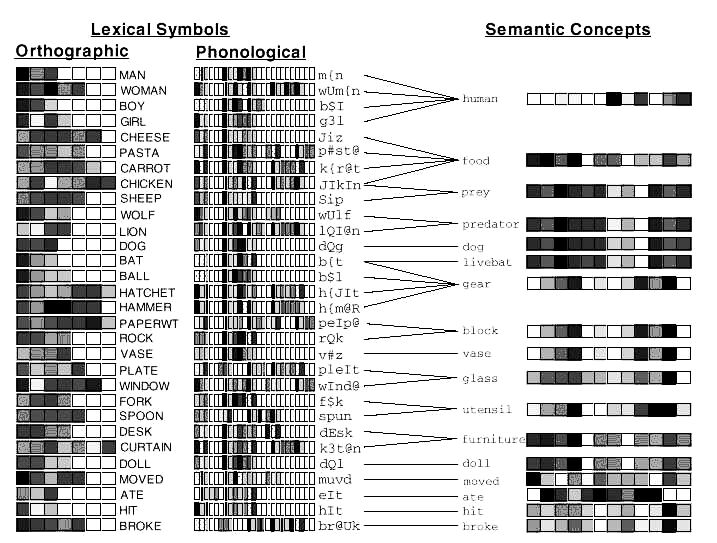
Wektory reprezentujące ortograficzne czy fonologiczne reprezentacje symboli utworzyć można przypisując literom czy fonemom przypadkowe wartości, wektory reprezentacji semantycznej otrzymuje się z sieci Kohonena, ucząc ją przez pobudzanie elementów tej sieci (pełniących rolę neuronów) wektorami reprezentującymi symbole analizowanego tekstu. Na poniższym rysunku ortograficzna reprezentacja symbolu "pies" odwzorowana jest na reprezentację semantyczną tego symbolu.
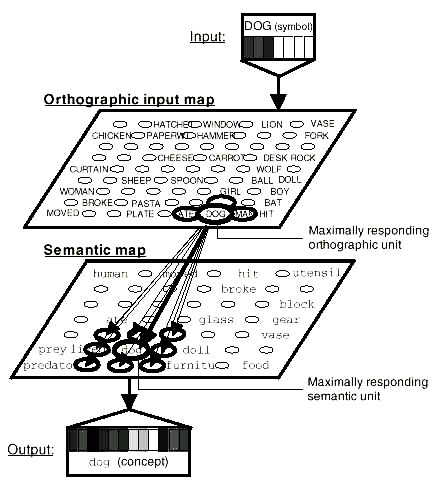
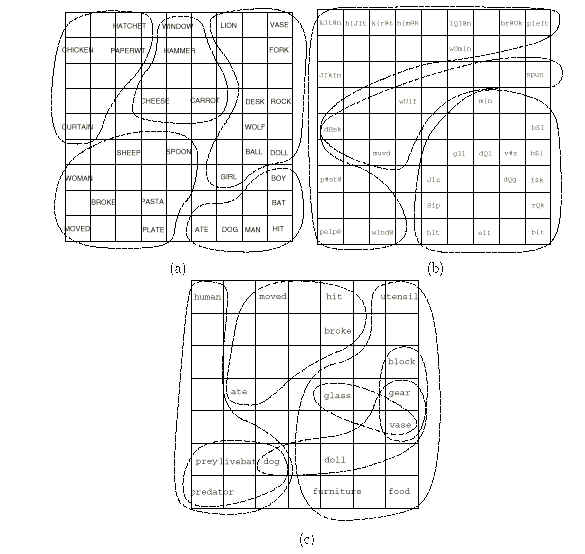
W wyniku takiego pobudzania algorytm uczenia sieci Kohonena przypisze elementom tej sieci takie wektory, które będą zbliżone do wektorów symboli o podobnym znaczeniu, umieszczając te symbole obok siebie na mapie. Podanie mapie semantycznej wektora reprezentującego postać ortograficzną (i fonetyczną) symbolu spowoduje największe pobudzenie się tych jej elementów, które odpowiadają za postać semantyczną, i nieco mniejsze pobudzenie elementów powiązanych semantycznie z przedstawionym symbolem. Jak widać na rysunku poniżej chociaż na mapie ortograficznej a) i mapie fonologicznej b) symbole nie są ze sobą powiązane to na mapie semantycznej możemy zauważyć powstawanie kategorii, obejmujących kilka symboli położonych blisko siebie.
Podobny efekt automatycznego powstawania semantycznych reprezentacji uzyskać można przedstawiając symbole w wielowymiarowej przestrzeni cech i używając algorytmów redukcji wymiarowości do ustalenia jak najmniejszej przestrzeni, w której zachowane są relacje podobieństwa. Landauer i Dumais (1977) stosując analizę semantyczną czynników ukrytych (Latent Semantic Analysis) i skalowanie wielowymiarowe stwierdzili, iż potrzeba około 300-wymiarowych reprezentacji wektorowych by odtworzyć relacje podobieństwa pomiędzy 50. tysiącami symboli. Również w naszych własnych badaniach stwierdziliśmy (Duch, Naud 1996), że nieliniowe mapowanie przestrzeni cech za pomocą skalowania wielowymiarowego (MDS) odtwarza poprawnie relacje podobieństwa pomiędzy zwierzętami należącymi do różnych kategorii. Otrzymane mapki są bardzo podobne do tych, które otrzymuje się z wyników eksperymentów.
Opisane w poprzednim rozdziale metody tworzenia reprezentacji semantycznych zostały na razie tylko w niewielkim stopniu wykorzystane do szukania informacji semantycznej. W ramach projektu WebSOM, wykorzystującego hierarchię sieci Kohonena do analizy tekstów, stworzono w automatyczny sposób mapy, kategoryzujące ponad milion dokumentów (były to list z różnych grup Usenetu). Wyniki obejrzeć można pod adresem:
https://websom.hut.fi/websom/

Pojawiające się tu symbole występują wiele razy w różnych kontekstach. Można stąd wybrać kontekst najbardziej interesujący, bez konieczności przeglądania wielu dokumentów, w których występuje dane słowo kluczowe. Metodę tą zastosować można również do analizy tekstów medycznych.
Bardzo zaawansowane są prace amerykańskiej agencji DARPA https://www.darpa.mil/ nad metodami semantycznego wyszukiwania informacji w bardzo dużych bazach danych. Chociaż prace te prowadzone są głównie z myślą o zastosowaniach wojskowych powinny doprowadzić do lepszych metod wyszukiwania i filtrowania informacji w Internecie, przydatnych również w medycynie. W ramach projektu cyfrowych bibliotek (digital libraries), rozwijanego w USA, realizowany jest "The Interspace Research Project", w którym metody inteligencji obliczeniowej zaprzęgnięto do automatycznego tworzenia map kategorii symboli, przestrzeni koncepcji i ekstrakcji koncepcji z multimedialnych baz danych. Metody te stosuje się zarówno do literatury specjalistycznej w różnych gałęziach techniki, jak i medycyny.
Projekt MedSpace, który można obejrzeć na stronach https://www.canis.uiuc.edu/, stworzył już prototyp systemu wyszukiwawczego, w którym program umożliwia mu przeglądanie drzewa klasyfikacji zagadnień i wybór odpowiedniej przestrzeni koncepcji. Po wpisaniu poszukiwanego terminu (np. breast cancer gene) w przestrzeni koncepcji otrzymuje skojarzone z nim frazy, pozwalające mu na znalezienie specyficznych terminów, np. gen BRCA1, co prowadzi do tytułów i abstraktów prac na poszukiwany temat. Przykłady użycia tego narzędzia do szukania informacji w bazach National Library of Medicine oraz w dostępnych w Internecie bazach Medline pokazane są na stronie projektu MedSPace.